과기부, 표준안 TTA에 제안...내년 6월 최종 확정 예정
데이터댐 핵심자원 'AI 데이터' 개념-세부사항 등 정립
AI 데이터 품질 걸음마 수준...구글 등도 43~83% 불과

[포쓰저널] 디지털 뉴딜 ‘데이터 댐’의 핵심자원인 인공지능(AI) 데이터 관련 품질의 개념과 범위, 세부 요구사항 등을 정립한 표준안이 마련된다.
데이터의 품질은 인공지능 기술과 서비스의 성능을 좌우하는 핵심요소이지만 그동안 일정한 표준이 없어 관련 산업 발전에도 장애요소로 작용했다.
과학기술정보통신부는 6일 AI 데이터 품질 표준안을 한국정보통신기술협회(TTA) 내의 단체 표준화 기구(TTA PG 1005, 인공지능 기반 기술)에 공식제안한다고 5일 밝혔다.
표준안은 관련 전문가 등의 의견수렴 절차를 거쳐 내년 6월 최종 채택·확정될 전망이다.
앞으로 관련 내용을 국제표준화 성과로도 이어질 수 있도록 추진할 계획이다.
AI 데이터 품질 수준은 세계적으로도 아직 높지 않은 상황이다. 마이크로소프트 COCO나 구글 오픈 이미지 등이 4~6년 넘게 구축·업데이트해온 개방 데이터셋의 경우에도 데이터 정확도가 43~83% 수준에 불과하다.
이는 세계적으로 AI능 데이터 품질에 대한 체계적인 방법론이 정립되지 않은 것이 중요한 원인으로 분석된다.
우리나라는 4월 ‘인공지능 국제표준화회의(ISO/IEC JTC1/SC42)’에 AI 데이터(딥러닝) 품질 관련 사항을 신규 과제로 제안해 채택되는 등 이제 막 논의가 시작되는 초기단계다.
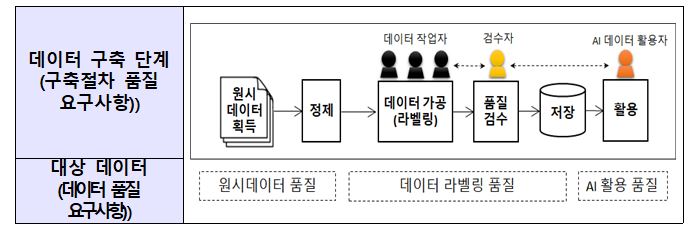
과기정통부는 TTA와 한국정보화진흥원을 통해 2019년 개발된 ‘AI 학습용 데이터 구축 및 품질관리 공통기준‘을 해외사례 분석, 인공지능 및 품질관리 전문가 자문 등을 거쳐 이번 표준안을 개발했다.
표준안은 자연어처리, 자율자동차, 의료, 농축수산, 제조 등 다양한 분야에서 공통적으로 적용 가능한 범용표준의 형태로 개발됐다.
데이터의 품질을 체계적으로 확보하고 상호호환성을 제고할 수 있도록 데이터 수집?정제?가공?품질검증?활용 등 전주기 단계별로 필요한 표준절차와 품질 요구사항 등을 정의하고 기본적인 데이터 규격을 담고 있다.
구체적으로는 △ 원시데이터 수집단계의 다양성, 사실성 등의 품질 요구사항과 파일 포맷, 해상도 등의 기술 적합성 요구사항 △ 정제단계의 데이터 중복방지 및 비식별화 조치 요구사항 △ 가공단계의 객체 분류체계 및 라벨링 규격 요구사항 △ 품질검수·활용 단계의 유효성 등 검수 요구사항·방법 등으로 구성돼 있다.
과기정통부는 이번 표준안을 이미 추가경정예산 사업 과제(10대 분야, 150종 데이터)에 적용하고 있다.
TTA 내의 단체 표준화 기구(TTA PG 1005, 인공지능기반기술) 내의 산·학·연 전문가 의견수렴을 거쳐 신속하게 단체 표준화를 추진한다는 방침이다.
관련 사항을 국립전파연구원 등을 통해 ‘인공지능 국제표준화회의(ISO/IEC JTC1/SC42)’에 제안하는 등 국제표준화의 성과로 이어지도록 할 계획이다.
연말까지 표준안을 바탕으로 AI 개발자, 공공기관 관계자 등이 AI 데이터의 품질을 보다 체계적으로 계획·관리할 수 있도록 하기 위해 자세한 설명 등을 포함하는 ‘인공지능 데이터 품질관리 가이드’를 개발·배포할 방침이다.
과기정통부 관계자는 "이번에 개발된 표준안이 디지털 뉴딜 ‘데이터 댐’의 핵심자원인 인공지능 데이터의 품질을 향상시키고, 나아가 국가 전반의 인공지능 기술과 서비스의 성능을 높이는데 크게 기여할 것으로 기대하며, 앞으로 국제표준화를 선도하고 우리나라가 인공지능 강국으로 도약하는데 더욱 노력할 계획이다"고 했다.